GraphQL API
Contents
Enonic is a highly flexible CMS, capable of delivering content in many ways. In this chapter we will focus on delivery via the out-of-the-box GraphQL API.
Now that we’ve created some content, let’s see how we can access and use it in via API - headless style.
Guillotine
Introducing Guillotine, the app that’s responsible for automatically generating a GraphQL APIs for your content.
Guillotine should be pre-installed based on the Essentials template you used when setting up your sandbox. It is available on Enonic Market, and may also be installed manually.
Query playground
Back in Content Studio, you should now have access to a new item called Query Playground in the left green widget sidebar. Open it, and you should see this:
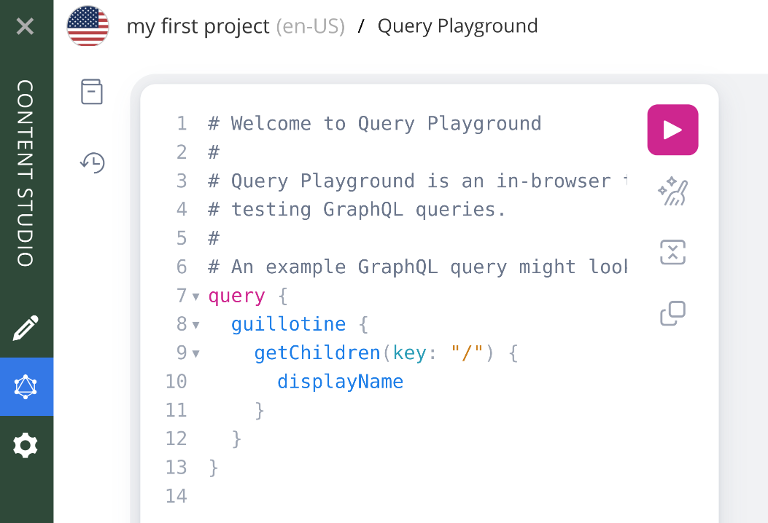
Query playground is an interactive GraphQL API explorer. You enter your query in the text area to your left and when you execute it, you’ll get the results of the query on the other side of the screen.
GraphQL is a graph "query language". It allows you to create highly specific queries for exactly the content that you need (visit the official GraphQL docs to learn more).
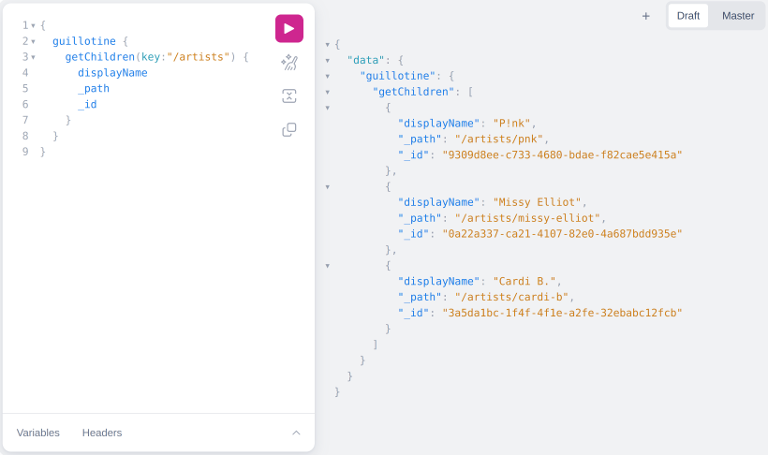
As an example on how to retrieve some minimal info about your previously created artists, run the following query:
{
guillotine {
getChildren(key:"/artists") {
displayName
_path
_id
}
}
}After running, you should get something like this on the right area:
Buttons
Before trying to come up with complex queries, let’s make familiarize ourselves with Query Playground.
| Icon | Description | Shortcuts |
|---|---|---|

|
Play - Execute your query |
ctrl+enter |

|
Prettify - Format your query, removing comments and unecessary spaces / indentation |
ctl+shift+p |

|
Merge fragments - Rewrites your query based on the declared fragments |
ctl+shift+m |

|
Copy - Copy your query to your clipboard. |
ctl+shift+c |

|
Docs - Show the API documentation |
|

|
History - Shows all previously executed queries |
|

|
Tab - Creates new tabs for you to manage testing multiple queries |
|

|
Re-fetch schema - Reloads your GraphQL schemas based on recent changes |
|

|
Shortkeys - Displays all short keys that can be used in Query Playground |
|

|
Settings - Opens settings dialog |
|
|
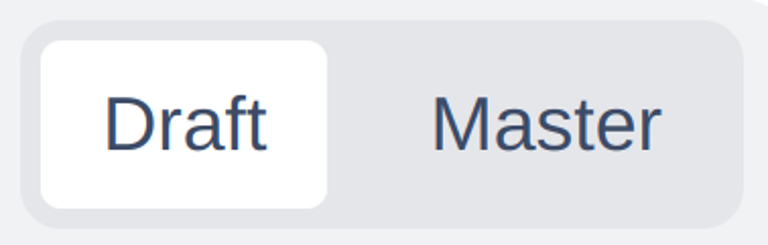
Draft / master toggle_ - Switch between querying draft or master branch (published items) |
Schemas
Now, locate and click on the docs button. On this opened section you have detailed info about all schemas available on your project.
On the top search bar in the docs section, search for artist and locate the com_example_myproject_Artist schema:
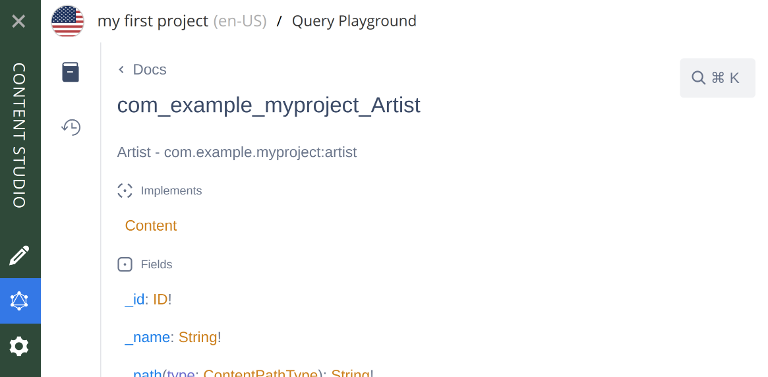
Note that it’s said that the Artist schema implements the Content schema. This basically means that the Artist schema will have the structure defined by the Content schema, together with possibly some additional structure… in this case, that additional structure is a data field, defined by com_example_myproject_Artist_Data schema:

| Note that this matches the structure defined by the Artist content type, which is a natural thing to expect. |
Querying with inline fragments
We’ve used the Docs section to inspect the structure of the Artist schema. Let’s now, based on a broader understanding of this schema, we’ll query to get proper data from artists.
Close the docs section, head back to the text area to edit your query and remove displayName, _path and _id from the query we introduced earlier.
Now, with your cursor on the inner curly braces of the query, press ctrl+space to get a list of suggestions about what fields you can request on your query:
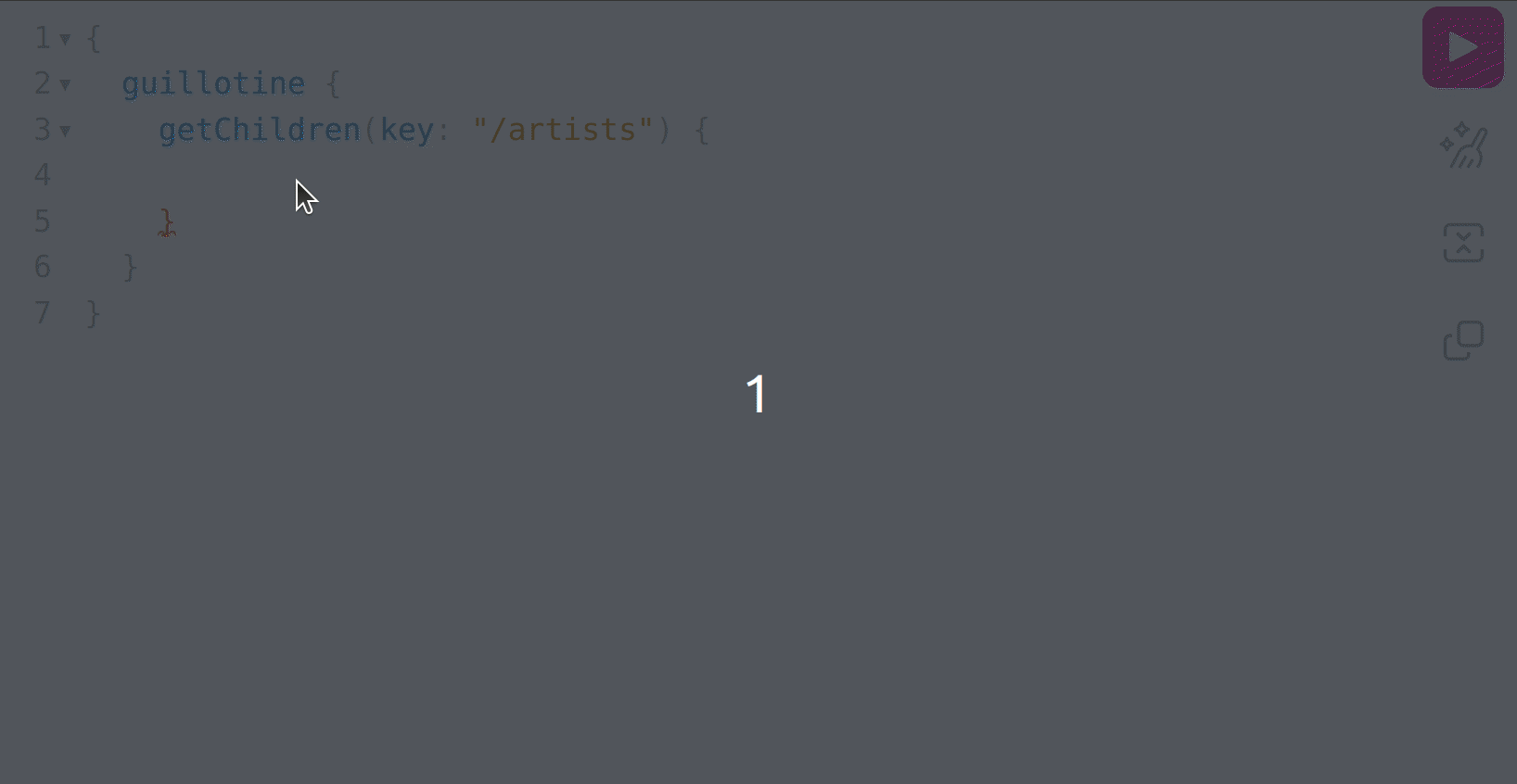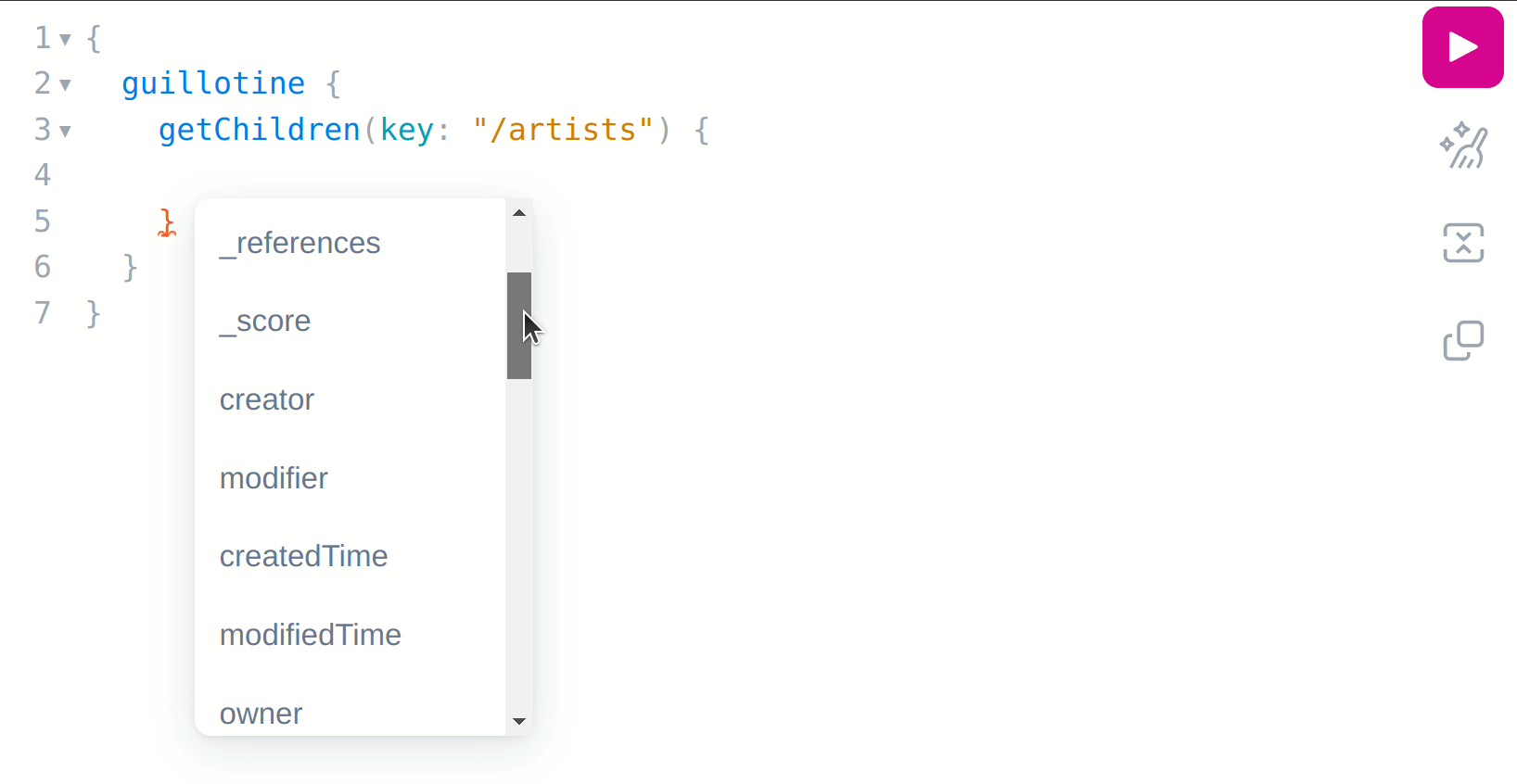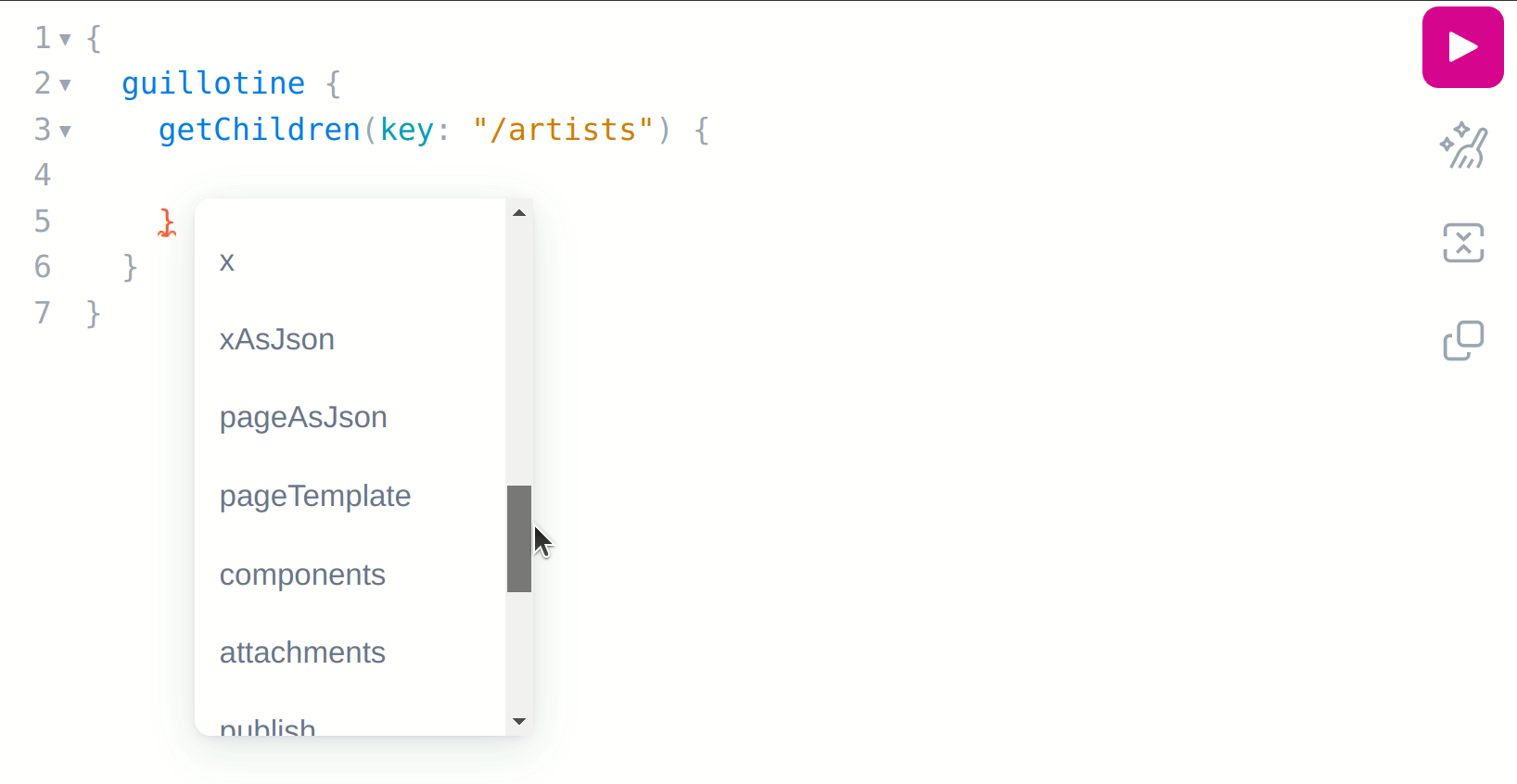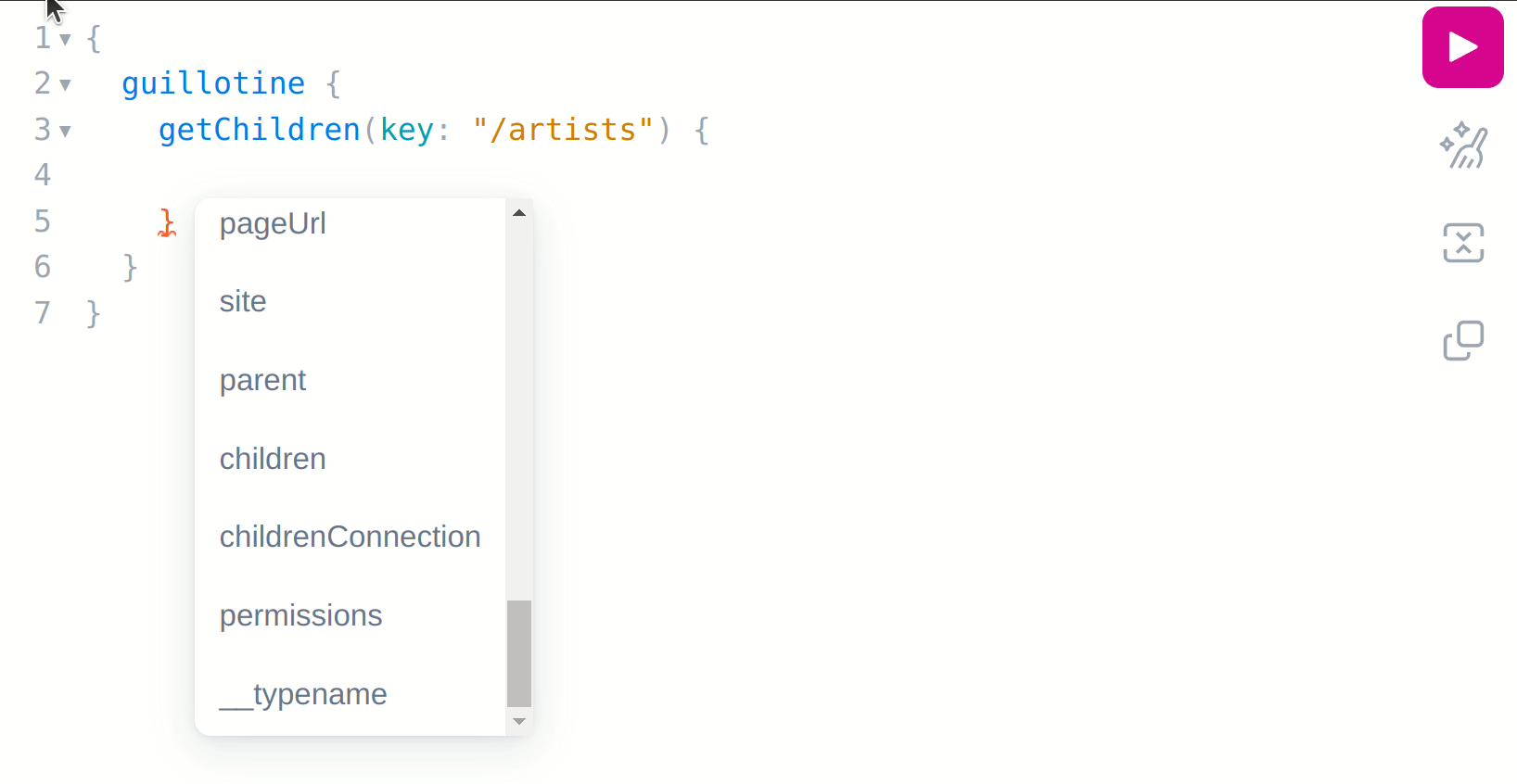
As can be seen, we do not have the artist name and about fields available, and the reason for that is because the getChildren field can return any content that implements the Content schema, but it can’t directly infer what schema that is, which in this case is the com_example_myproject_Artist schema:
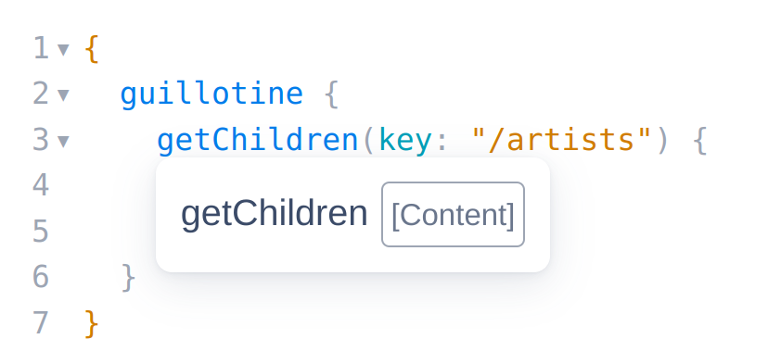
So to proceed, we use inline fragments:
{
guillotine {
getChildren(key: "/artists") {
... on com_example_myproject_Artist {
_id
data {
name
about
}
}
}
}
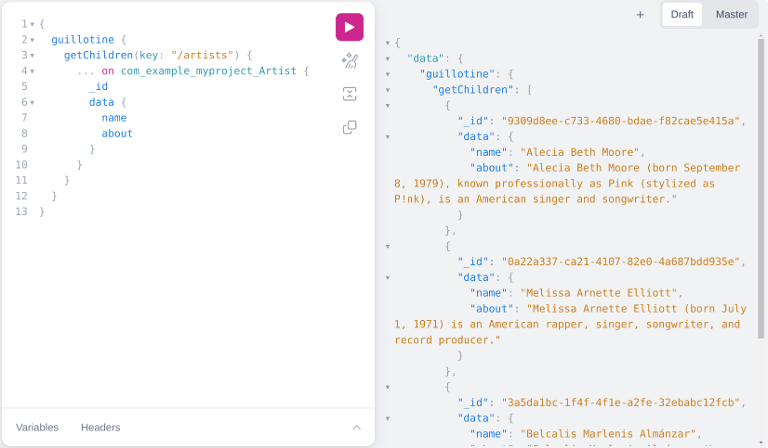
}With this, we basically built a query that understands that under "/artists" path we have content types of Artist, and based on this we can request general content data, such as _id, but also specific content data, such as the artist name and about:
Query with dataAsJson
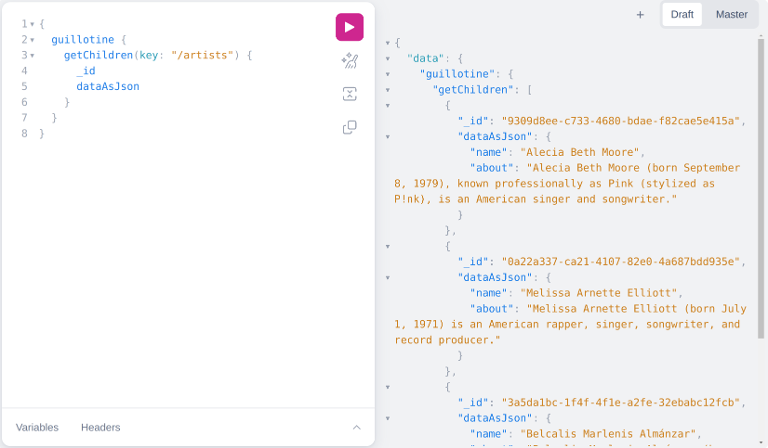
If you don’t need or care about types when creating your queries, you can ignore the previously presented inline fragment approach and use the field dataAsJson:
{
guillotine {
getChildren(key: "/artists") {
_id
dataAsJson
}
}
}
Advanced queries
We’ll now introduce and show examples of usages of different fields underneath the guillotine field, that allow us to search the system for specific data.
QueryDsl
There is a queryDsl field underneath guillotine which allows you to search the system for what you want (the "Dsl" stands for "Domain Specific Language").
The syntax is based on two types of operators: Expressions and Compound.
-
Expression -
Used to check particular fields for various native and analysed values.
-
Compound -
Used to logically combine various expressions and compounds to fetch nodes based on complex conditions.
In order to exemplify this field usage on some queries, we’ll query on the data set we’ve created so far on in this guide:
{
guillotine {
queryDsl(
query: {
term: {
field: "type",
value: {
string: "com.example.myapp:artist"
}
}
},
first: 1,
sort: {
field: "displayName",
direction: DESC
}
) {
_id
displayName
}
}
}Note that this query is getting the last artist that is alphabetically sorted by name, regardless of where the content type is located in the tree structure.
The following GraphQL query uses the n-gram functionality to find all the artists that have a term (part of a text) that starts with rap somewhere in their data:
{
guillotine {
queryDsl(
query: {
boolean: {
must: [
{
term: {
field: "type",
value: {
string: "com.example.myapp:artist"
}
},
ngram: {
fields: ["_allText"],
query: "rap"
}
}
]
}
},
sort: {
field: "displayName",
direction: DESC
}
) {
_id
displayName
}
}
}Naturally, you can also use the standard boolean operators to combine or negate clauses. If you wanted to find all artists that mention both rapping and singing, you could try a query like this:
{
guillotine {
queryDsl(
query: {
boolean: {
must: [
{
term: {
field: "type",
value: {
string: "com.example.myapp:artist"
}
}
},
{
ngram: {
fields: "data.about"
query: "rap sing"
operator: AND
}
}
]
}
},
sort: {
field: "displayName",
direction: DESC
}
) {
_id
displayName
}
}
}If you’ve previously used Elasticsearch API to query data, you’ll be quite familiar with how queryDsl works! |
| To learn more about queryDSL capabilities, visit the DSL reference |
QueryDslConnection
Just like there is a queryDsl field underneath guillotine, the API also provides other fields such as queryDslConnection.
We’ll not go into much details, but basically, the fields with connection in their name have new parameters for aggregating and paginating data.
To finish this chapter, we’ll add a new birthyear field to the artist content type, update all artist to have data on this field, and then use queryDslConnection field to get aggregated data. Let’s get to work!
-
Start by updating the Artist content type to the following structure:
<content-type>
<display-name>Artist</display-name>
<description>Information about an artist</description>
<super-type>base:structured</super-type>
<form>
<input name="name" type="TextLine">
<label>Name</label>
<help-text>
The artist's name (if different from their professional moniker).
</help-text>
</input>
<input type="TextArea" name="about">
<label>About the artist</label>
</input>
<input type="Date" name="birthday" >
<label>Birthday</label>
</input>
</form>
</content-type>If are not running the project in dev mode (enonic project dev introduced in the previous $chapter), make sure to run enonic project deploy in the terminal on the project’s root directory |
-
Update each of the previously created artists with the following dates:
-
P!nk: 1979-09-08
-
Missy Elliot: 1971-07-01
-
Cardi B: 1992-10-11
-
-
Go back to Query playground and click on the re-fetch schema button. This will update the Artist data schema to contain the birthday structure, which is in sync with the Artist content type structure
-
Run the following query on the playground:
{ guillotine { queryDslConnection( query: { boolean: { must: { term: { field: "type" value: { string: "com.example.myapp:artist" } } exists: { field: "data.birthday" } } } } aggregations: { name: "generationsAggregation" dateRange: { field: "data.birthday" ranges: [ { key: "The Greatest Generation" from: "1901" to: "1927" } { key: "The Silent Generation" from: "1928" to: "1945" } { key: "The Baby Boomer Generation" from: "1946" to: "1964" } { key: "Generation X" from: "1965" to: "1980" } { key: "Millennials" from: "1981" to: "1996" } { key: "Generation Z" from: "1997" to: "2012" } { key: "Gen Alpha" from: "2013" to: "2025" } ] } } ) { aggregationsAsJson } } }
And this are the results
{
"data": {
"guillotine": {
"queryDslConnection": {
"aggregationsAsJson": {
"generationsAggregation": {
"buckets": [
{
"key": "The Greatest Generation",
"docCount": 0,
"from": "1901-01-01T00:00:00Z",
"to": "1927-01-01T00:00:00Z"
},
{
"key": "The Silent Generation",
"docCount": 0,
"from": "1928-01-01T00:00:00Z",
"to": "1945-01-01T00:00:00Z"
},
{
"key": "The Baby Boomer Generation",
"docCount": 0,
"from": "1946-01-01T00:00:00Z",
"to": "1964-01-01T00:00:00Z"
},
{
"key": "Generation X",
"docCount": 2,
"from": "1965-01-01T00:00:00Z",
"to": "1980-01-01T00:00:00Z"
},
{
"key": "Millennials",
"docCount": 1,
"from": "1981-01-01T00:00:00Z",
"to": "1996-01-01T00:00:00Z"
},
{
"key": "Generation Z",
"docCount": 0,
"from": "1997-01-01T00:00:00Z",
"to": "2012-01-01T00:00:00Z"
},
{
"key": "Gen Alpha",
"docCount": 0,
"from": "2013-01-01T00:00:00Z",
"to": "2025-01-01T00:00:00Z"
}
]
}
}
}
}
}
}Which shows that two of those artists are from Generation X, and one of them is a Millenial.
Dive deeper
-
For more query examples and information about how to get up and running with Guillotine, you can check out Quick introduction guide or the Guillotine docs
-
If you want to understand how to extend available schemas on the GraphQL Api, you can head to Extending section on Guillotine docs or check some examples on this guide
-
If you want to learn more about GraphQL in general, the Introduction to GraphQL documentation is a good place to start
Summary
In this chapter you’ve learned about the Guillotine app and its API. Next up let’s have a look at how XP deals with files (aka media).