Deployment strategies
Contents
Depending on your requirements for scalability, performance and isolation, there are a number of different deployment strategies to consider.
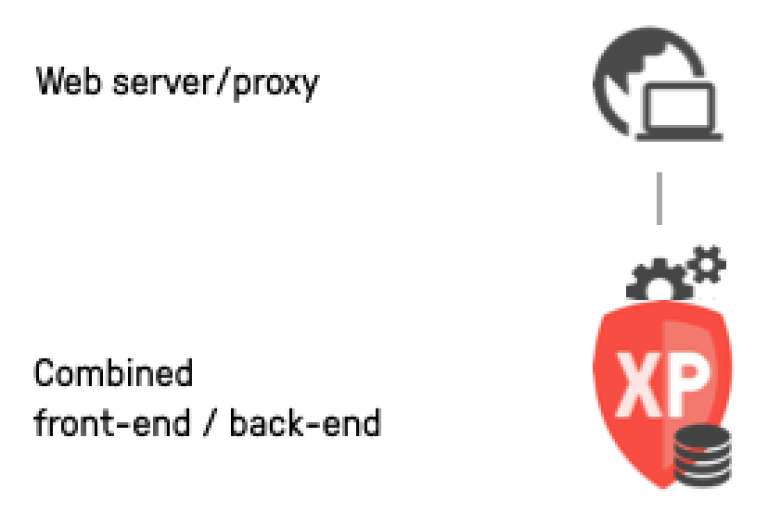
Single node
The minimal deployment of Enonic XP is limited to a single XP node. Similar to the XP SDK, this node will act as both front-end and back-end, running applications as well as handling storage.
In this case, you will simply need a local file system to store your indexes, blobs (raw data) and backups.
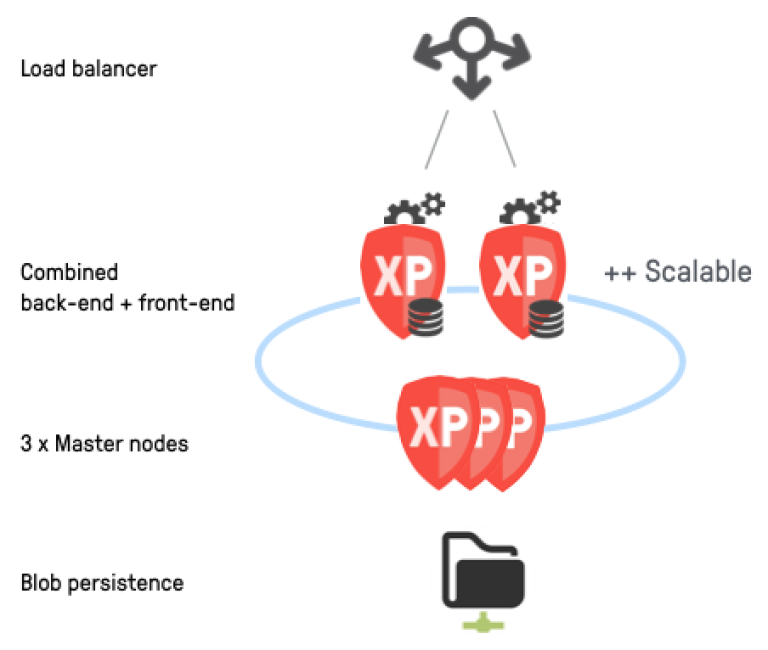
Basic cluster
A basic XP cluster will provide redundancy, scalability and increased uptime for your services.
Enonic XP uses a distributed storage model without a dedicated master. It is crucial that the cluster always has one, and only one master. If your cluster at some point has more than one master, we have a so-called "Split brain" situation. Split brain means that you are essentialy running multiple clusters, where each cluster thinks it is the only one. As writing may occur in two different locations, this may result in loss of data or inconsistency.
To mitigate this, any cluster must at least have three nodes. At any time, only one of the nodes will act as master. Masters are elected based a quorum. With only two nodes, the cluster will not be able to form a quorum if one of the nodes fall out.
Under strain, a master node may start to perform slowly and behave unpredictably. A failing master may cause problems for your entire cluster. To avoid this scenario, one should always deploy three dedicated master nodes, and move processing to dedicated worker nodes. This should guarantee a stable set of master nodes to control your cluster, including where and how data is distributed.
This means that a minimal cluster requires at least five nodes, three master nodes, and two worker nodes. In theory, you could just start one worker node, but then again, that would not be a proper cluster.
In addition to running multiple nodes, clusters also have additional infrastructure requirements when compared to a single node:
-
A shared or distributed file system for storing blobs and for snapshotting, dump and export purposes
-
A load balancer is required to distribute incoming traffic to the various nodes in the cluster.
| Due to the limited stress on the master nodes, they can normally be of smaller size than worker nodes. |
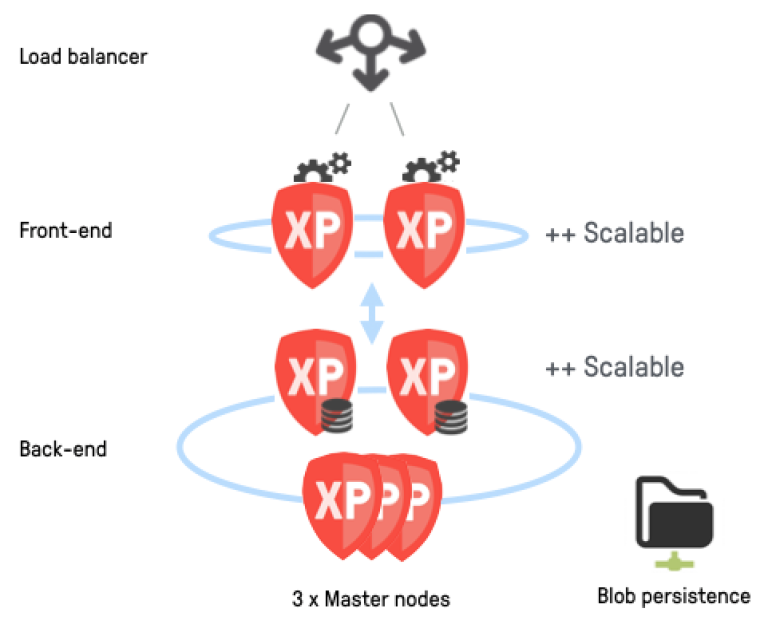
Autoscaling cluster
If you want to quickly scale the number of instances of your cluster up or down based on sudden changes in traffic/load, you shold consider this option.
This scenario builds on the dedicated master nodes strategy, but now also differenciates between front-end and back-end nodes.
The front-end nodes will act as runtimes for the apps/site/admin and handle the incoming traffic. The back-end nodes will handle state, indexing and data persistence. The back-end nodes are typically able to serve multiple front-end nodes, as the request processing if often heavier on the front-end nodes.
Even if data nodes may also be scaled up an down, resizing front-end nodes is faster and easier than when it comes to data nodes. The downside of splitting into front-end and back-end nodes is a slightly higher latency when accessing your data.
| You may consider if you need different type of CPU/Memory assigned to the different node types. Typically, front-end nodes may require less memory than back-end nodes. |
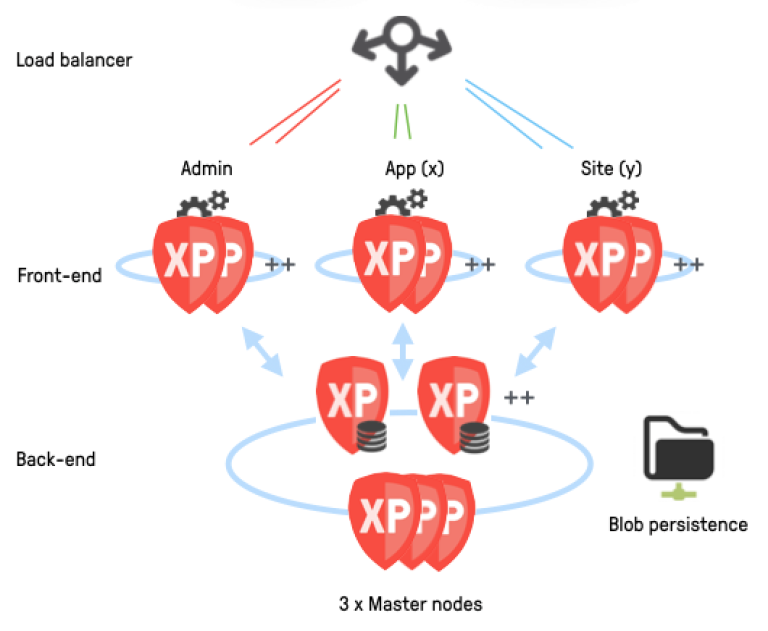
Micro service cluster
For enterprise class deployments, we recommend the micro service cluster strategy. It builds on the autoscaling cluster approach, but further aims to isolate the various services better. For instance, you might have dedicated nodes for the admin console, a specific site or app - all depending on needs.
You may even consider running selected services using combined nodes (handling both data and apps), for instance for admin nodes. In such a scenario, editors working in Content Studio minimally affect the performance of the other services.
The benefits of this strategy is a higher degree of control over each service and how it can be scaled, similar to how most cloud native micro service platforms work.
| In this scenario, each individual front-end service may be configured with different CPU/Memory and scaling options as required. |